











相关标签
网址预览
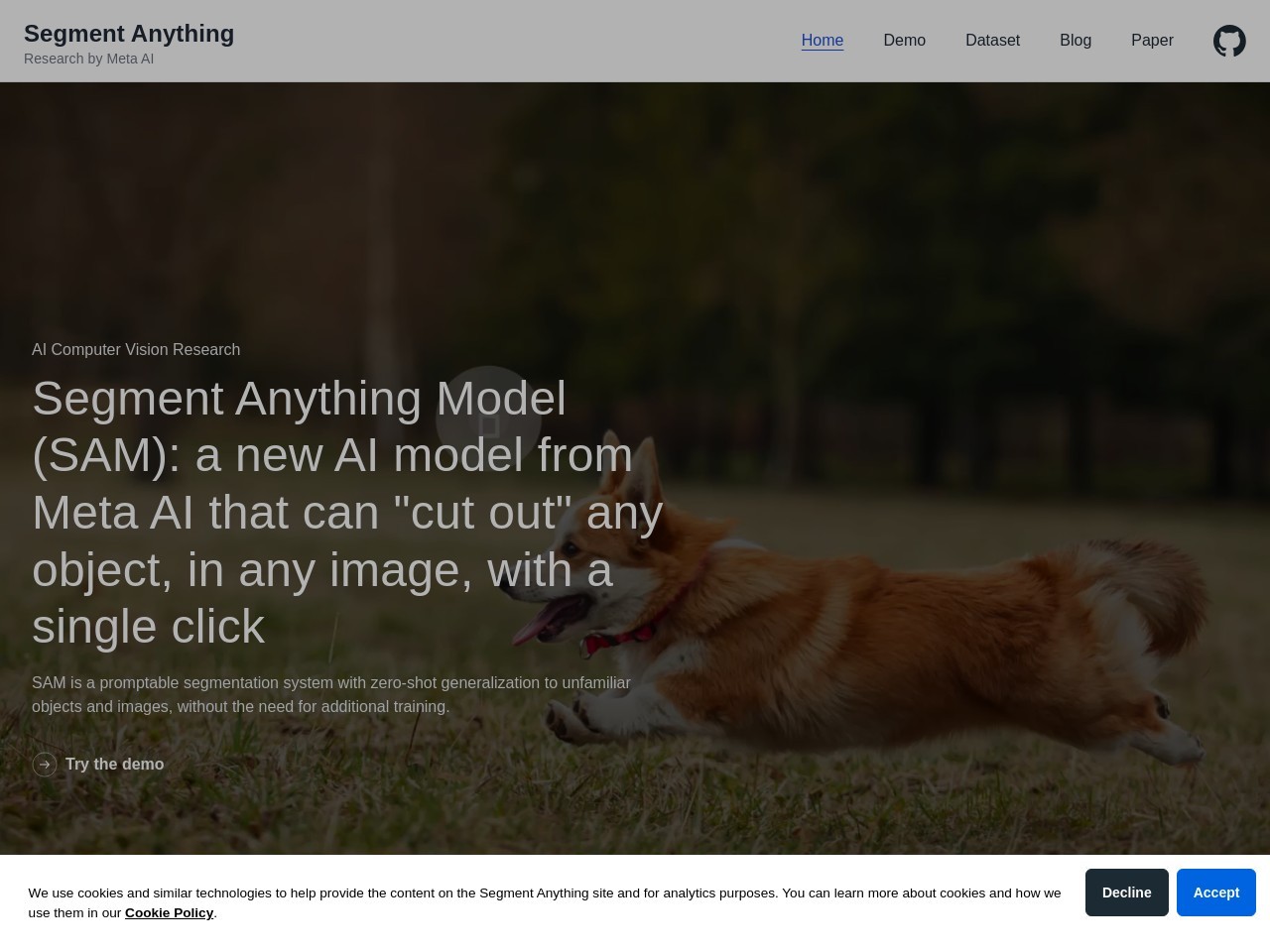

Meta AI 发布了名为 Segment Anything Model(SAM)的新 AI 模型,其相关信息如下:
模型功能
模型训练
模型设计
其他信息
相关导航









暂无评论...




















Ai工具集 - 人工智能 - 是专注Ai人工智能软件推荐的免费AI工具集合网站,为全球办公人提供最新、最全面的ai人工智能工具软件app下载和使用指南,助您更好地应用AI人工智能技术。是实现高效办公轻松生活的实用网址导航网站!


Meta AI 发布了名为 Segment Anything Model(SAM)的新 AI 模型,其相关信息如下:
 渝公网安备50011802010872
渝公网安备50011802010872